Calculating π from random numbers
Matt Parker of Stand-up Maths fame has a yearly series where he tries to calculate π by various,(sometimes ridiculous) techniques. This is a personal favourite, where he uses Avogadro’s number and it was more accurate than I would have expected. The rest of this post is based on this video from 2017 and basically boils down to the fact that the probability of two random numbers being co-prime is 6/ π^2. This comes from a famous problem in mathematical analysis called the Basel Problem and was solved by Euler
I have been using a lot of Claude at work and am trying to step away from it for my personal coding. After a lot of bike-shedding in getting my vim-go configured just right, I decided to try this out. The core problem is very simple and just involves calculating the GCD of 2 numbers and doing that for a lot of numbers to estimate the probability. I wanted to use some of the standard profiling tools to visualise the performance and optimise some of the low hanging fruit.There are probably smarter ways of calculating GCD ( or checking if numbers are co-prime), but that is not point of this post.
I ran the benchmarking tests on a Linux environment powered by an AMD Ryzen 7 5800H processor (8 cores, 16 threads)
Baseline
I am generating numbers in the range 1 - 1 billion and counting the results from 1 billion pairs.
The first naive implementation doesnt try to do anything clever and just hammers away at the problem.
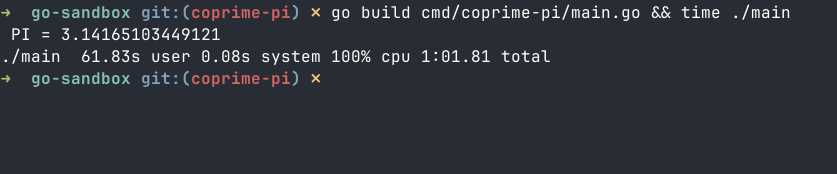
Looks like we have π, if we dont look too closely. It took about a minute to run. Wall time and cpu time are pretty much the same, as expected since there is only 1 thread running
Enable profiling
I enabled cpu profiling using Go’s runtime/pprof package
After running the code again, a cpu.prof is created and the data can be visualised and seen in your browser with
go tool pprof -http=:8080 cpu.prof
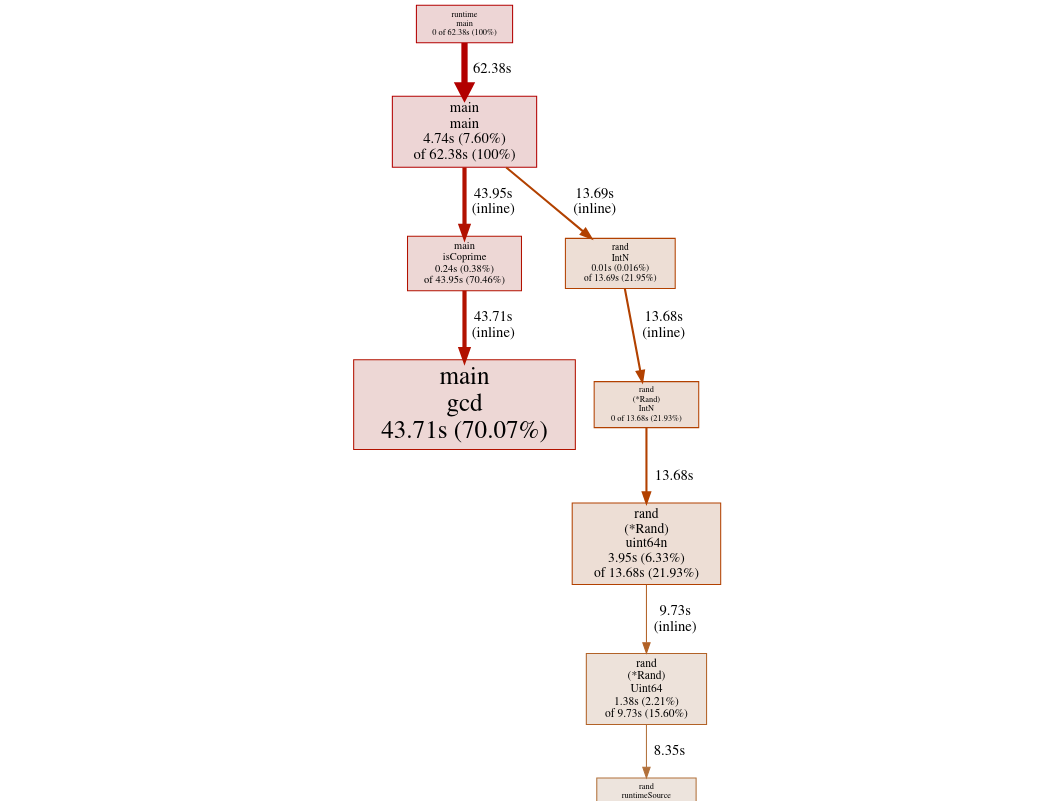
Again nothing too surprising, about 70% of time is in the gcd calculation and 30% is generating random numbers. At this point, I am not sure how to generate random numbers faster, but we will cross that bridge when we get there, if we need to.
Quick win
This is based on the idea that we dont really need to calculate the GCD for all the pairs. For example, if both numbers are even, we know that they are not coprime. This will occur about 25% of the time.

I added some code to short-circuit the isCoprime function, if the inputs are either multiples of 2 or multiples of 3.

This has knocked off about 13 seconds from the time, so around 20% less time
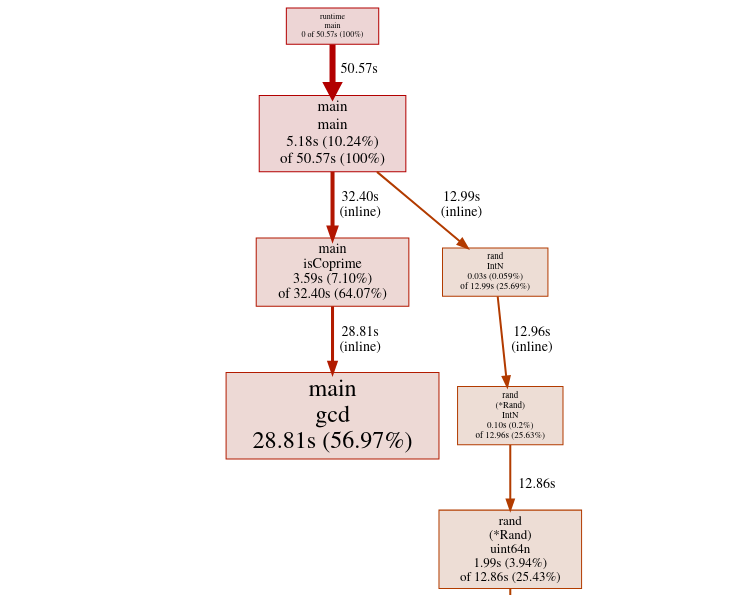
More Power
Hey I paid for all those cpu cores, and only 1 of them is being used. Also Go is great for concurrency with channels and goroutines.
I have now implemented the producer-consumer pattern. Producers now generate random numbers and sends them as jobs to a channel. Consumers get the jobs from the channel, check if they are co-prime and eventually the number of coprimes get totalled up. What could go wrong?

Turns out, pretty much everything. The wall time for completing this has shot up to 350 seconds. The only silver lining is the cpu usage has gone up from 100% to 423%, which is still only about 25% of what it can go up to. System time, which is the amount of CPU time spent inside the Linux kernel has gone up to around 4 minutes. What is it doing there, which it didnt have to do earlier?
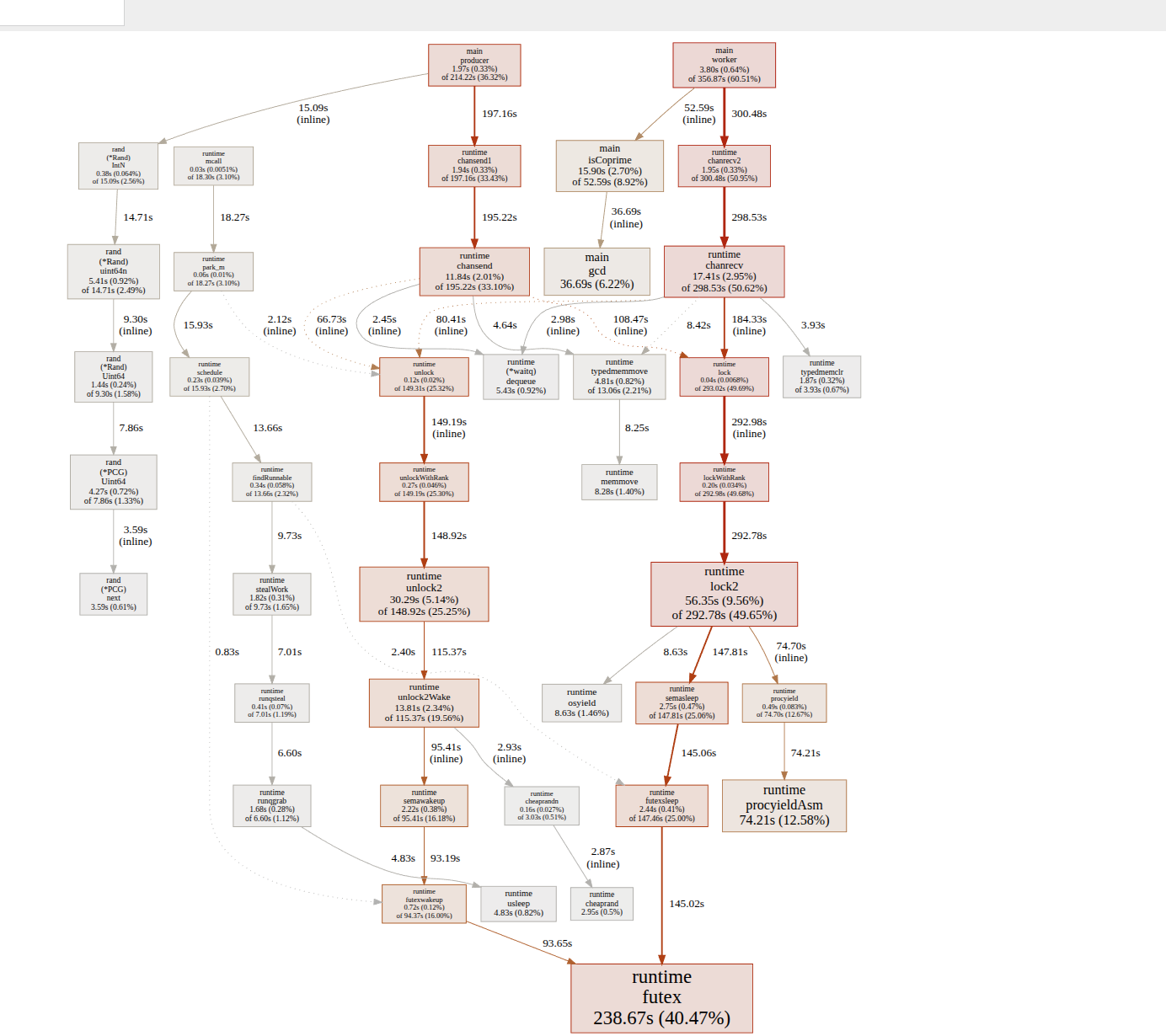
The answer was, waiting… a lot of it. Following the blocks in red from pprof output, the bulk of the time is now in the runtime.chansend and runtime.chanrecv, which is the overhead of using Go channels.
Taking a step back, the work being done was CPU bound and could be quickly done. The communication overhead between channels overshadows this time.
More Power, no channels
This was implemented with a bit of rework and removing the sending of messages via channels. All that happens is that we have a bunch of workers, they hammer away on their assigned number of tasks and then finally report back on the number of co-primes they found. This is essentially the same as our single threaded version, but now on all CPUs.
Go’s random generator can suffer from lock contention in this scenario. To avoid this, a local rand was created per worker

🎉 Execution time has fallen to 3.9s. system time (kernel) is now back to almost 0, the cpu time is 1567%, which matches the 16 cpus I have available. User time is around 60 seconds, as this includes time on all CPUs. This time is close to our initial time before any optimisation, so what we have done at this point is excellently parallelise stuff.
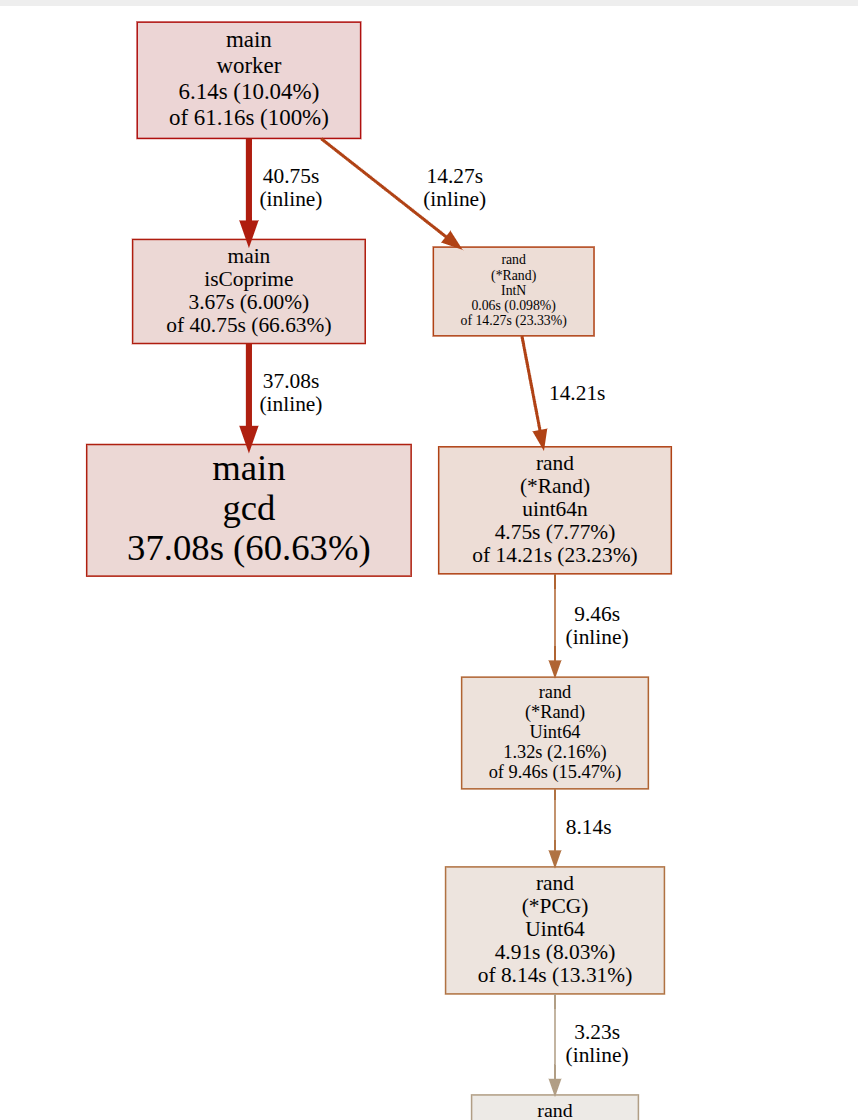
This also looks much better now and is only doing the work we actually want it to ( and not hanging around in the kernel space)
Summary
Using the output of time, when following the producer-consumer pattern, it was apparent that something was wrong because of the significant time in the kernel space. This coupled with looking at the visualisation of the profiling output, helped in rapidly identifying the bottleneck. The simpler solution worked better. The overhead of managing the channel is higher than the mathematical cost of computing the GCD.
There are some more optimised algorithms for calculating GCD like Stein’s algorithm, however the standard Euclidean algorithm is pretty good and more importantly easy to read